ChatGPT自作入門
本記事は、そこそこ自力で ChatGPTを自作するための解説&実装例となっています。ただ、現時点では ChatGPTの詳細は明かされていないようなので (2023-06-01)、実際には姉妹モデルである InstructGPTモデルを実装していくことになります。また、 InstructGPTモデルを作成するには、複数のモデルを訓練する必要があり、多量の計算資源や手動でのラベル付けが必要となります。なので、高性能なモデルを訓練するのは少し難しいですが、少なくとも実装だけはすることができます。
間違いなどを見つけた場合は、優しく教えていただけると嬉しいです。
目次
ChatGPTの概要
ChatGPTの生みの親である OpenAIのホームページには、 ChatGPTがどのように作られたのか、ということが軽く書かれています。しかし、 ChatGPTが InstructGPTモデルの姉妹モデルであるという以上のことは書かれていません (2023-06-01)。この InstructGPTモデルは、質問に対して答えを生成する NNモデルです。作成方法はこちらの論文に書かれており、以下の手順を辿ることで作成されます。
(1) ベースとなる一般 GPTモデルを訓練する。
(2) 1のモデルをプロンプト応答用にチューニングする。
(3) 2のモデルを強化学習を使い、更にチューニングする。
ということで、ここからはこれらの工程を1つずつ辿っていくことになります。
ベースとなる一般 GPTモデルを訓練しよう
GPTモデルの概要とアーキテクチャ
GPTモデルは文章を渡された時に、次の文字を予測するモデルです。例えば、 吾輩はという文字列が渡された時に、 猫などと出力します。また、出力された 猫を付け加えた 吾輩は猫を次の入力としてモデルに渡すと、 でなどと出力します。このステップを繰り返すことにより、 吾輩は猫であるといった文章が生成されます。
では、そんな GPTモデルの NNアーキテクチャはどんな感じかというと、本記事で使用するものは以下のようになっています。

各コンポーネントについては、各々の実装時に詳細な説明をするので、ここではマクロ的な説明をします。 GPTモデルは受け取った文章の次の文字を予測するモデルです。しかし、上の図では、ほぼ全ての文字を受け取って、全ての文字を出力しています。少し不思議に感じますが、これは GPTモデルが実際に全ての文字を予測しているためです。 GPTモデルはアーキテクチャの構造的に、 i番目の文字を予測する時には i番目以降の情報が使われないようになっています。例えば、下の図のように、 猫を予測する時はそれよりも左下の情報しか使われていません。

このように未来の文字の情報を受け取らないようにすることで、全ての文字を同時に予測することが可能になっています。
ちなみに GPTモデルの論文では、以下のような図がアーキテクチャとして書かれています。いくつかの違いを除けば (最終層、 Transformer層の数)、上の図と下の図のアーキテクチャはほぼ同じものとなっています。

データを用意する
GPTモデルは、文章の次の文字を予測するので、日本語の文章さえあれば訓練することができます。ということで、まずは日本語の文章を用意していこうと思います。今回は、こちらのAhmedさんのデータセットをお借りしようと思います。そこも自分で用意したいという方は Wikipediaのダンプなどから抽出してもいいのかもしれないです。
~ > head -n 5 wiki-sentences.txt テネシー大学、デューク大学、フロリダ大学などからのオファーもある中、彼が選んだのはノートルダム大学であった。 9月5日、シカゴ・ベアーズとプラクティス・スクワッドとして契約を結んだ。 12月19日、クリス・コンテが故障者リスト入りするのと入れ違いにアクティブロースター入りした。 クロード・ドビュッシーの曲を原曲にした楽曲をリリースした。 又、のちに山口裕加里が同曲をカバーした。
データを読み込む
では、データを Pythonで読み込みます。ただ、 NNモデルで文字を直接扱うのは少し厳しいので、ここではシンプルに各文字を数字にマッピングしておこうと思います。つまり、 {吾 → 0, 輩 → 1, は →2, …}といった感じのマッピングを作成します。
GPT-2や GPT-3では、 {吾輩 → 0, は → 1, 猫 → 2, である → 3, …}のような、もう少し纏まったレベルでのマッピングを行います。ただ、初めにトークナイザーばかり作り込むのも何とも言えないので、本格的な実装は後に回そうと思います。
事前知識: PyTorch
本記事では、主に PyTorchを使います。ただ、 PyTorchの基礎的な機能しか使わないので、この公式チュートリアルがわかるくらいの知識があれば、問題ないと思います。
実装: 入力と出力だけ
一度に GPTモデルを全て実装するのはキツイので、全体の流れや入出力の確認も兼ねて、必要最低限の部分だけを実装しようと思います。ということで、まずは下の図のような Word Embeddingと全結合層だけからなるモデルを実装します。

実装: Transformer
モデルの基礎部分が実装できたので、次に Transformerを実装していこうと思います。これは GPTモデルの論文内にある図の、水色の部分に相当します。
つまり、以下の一連のブロックを12回繰り返したものになります。
(1) Masked Multi Self Attention
(2) Layer Norm
(3) 全結合
(4) Layer Norm
一番目の Masked Multi Self Attentionというのは、 Multi-Head Self Attentionをベースにした NNブロックです。そこに GPTモデル用の変更を加え、 i文字目では i-1文字目までの情報しか使わないように抑制 (Mask)をかけています。ということで、まず初めに Multi-Head Self Attentionが何かという話なのですが、それに関する解説記事は巷に数多くあるので、申し訳ないのですが、今回はそれらを参考にしていただけるとありがたいです。個人的には、このMishaさんのツイートがとてもわかりやすいと思います。
では、次にどうやってマスクをかけるのかという話なのですが、 GPTモデルは i文字目を予測する時に i-1文字目までの情報しか使ってはいけません。そのため、 Attention機構中で i文字目以降を参照されると困ります。なので、 Attentionの計算中に、 weightの該当部分に -infをセットすることにより、 i文字目以降の情報を取ってくることを抑制 (Mask)することになります。詳細は、以下の実装例を参考にしていただけるとありがたいです。
実装: Positional Embedding / Positional Encoding
Attention機構は語順を理解できず、 Cats like dogsと Dogs like catsの見分けがつきません。なので、 Transformerを提唱した Attention is All You Needという論文では、文字位置に関する情報を入力に追加して、モデルに渡していました。私が勘違いしていない限り、 GPT用のマスキングを施した Attentionは少し事情が違い、 2層目以降の Transformerでは、文字位置を把握することも可能な気がします。ただ、性能の面からか、 GPTモデルの論文でも文字位置を入力に追加しています。
文字位置を伝える方法は色々とあり、GPTモデルの論文で採用されているのは、学習可能なバイアスを Word Embeddingに足し合わせて、トレーニングを通じて最適な方法を探す方法です。これは Positional Embeddingと呼ばれています。非常にシンプルなので、詳細については下にある実装例を確認した方が速いかもしれないです。
また、別の方法として、 Attention is All You Needの中では、位置情報を伝えるためのベクターを予め人力でデザインしておいて、 Word Embeddingに足し合わせています。これは Positional Encodingと呼ばれています。今回は GPTモデルの実装ということで詳細は省きますが、このkazemnejadさんのブログが直感的に理解しやすく、非常にわかりやすいと思いました。
実装: Byte Pair Encoding
ここまでは 1文字ずつモデルに渡して、 吾輩などの複数文字からなる単語を学習して認識してくれることを願っていました。しかし、頻出単語は単語レベルで纏めて渡してあげた方が性能が上がりそう、と言われればそんな気もします。
GPT-3の論文によると GPT-2や GPT-3では Byte Pair Encoding (BPE)というトークナイザーを使っているようです。 BPEでは、文字のマージ規則に従って文字を纏めていくことになります。例えば、マージ規則が [(吾, 輩) → 吾輩, (で, あ) → であ, (であ, る) → である]であるとします。その場合、 吾輩は猫であるという文章は
(1) 文字レベルに分解され 吾 / 輩 / は / 猫 / で / あ / るとなる。
(2) マージ規則を適用して 吾輩 / は / 猫 / であると纏められる。
(3) 各トークンは、対応する数字の IDに変換されてモデルに渡される。
という手順を辿ります。
また、辞書の作成方法もかなりシンプルで、
(1) 全ての文字を辞書に加える。
(2) 出現頻度の多い、隣接する文字のペアを規則に加えていく。
というロジックになっています。以下に説明用の簡単なコードを置いておきます。
コード (説明用なので実装しなくても大丈夫です)
- 実装例
- 実行例
以上が BPEの実装となります。上の実行例からもわかる通り、 BPEでは単語レベルではなく、 ableのようなサブワードと呼ばれる単位で区切られることになります (able自体は単語でもありますが...)。これにより、 backpropagationableのような未知語も、 back / propagation / ableのようなサブワードに分割し対応できるようになる、と言われています。
では、ここで BPEを日本語に適用したい訳ですが、日本語の文章をそのまま BPEにかけると、 [(猫, は) → 猫は, (猫, に) → 猫に, (猫, を) → 猫を]のように、助詞や助動詞とのマージが頻出するようになります。私が参考にした論文 (『日本語 Tokenizerの違いは下流タスク性能に影響を与えるか?』)では、既存の形態素解析器で単語にパースした後に、 BPEをかけているので、本記事でもそのように実装しようと思います。解析機は MeCabの Pythonラッパーを使用します。
以下の実装例では、マージ規則を生成しファイルに保存しています。トークナイズされた文章を保存することもできたのですが、後で他のデータもトークナイズする必要があるので、マージ規則を保存しています。
では、最後にトークナイザーを実装します。また、トークナイズされた文章を使ってモデルを訓練します。これで一般 GPTモデル完成となります。
Supervised Fine-Tuningモデルを訓練しよう
概要
ここでは、先ほど作成した GPTモデルを会話用にチューニングしていきます。今までは、 吾輩は猫であるのような文章を学習させていましたが、ここからは 吾輩は誰ですか?:猫のような 質問:答えもしくは クエリ:応答形式の文章を渡して、モデルを fine-tuningしていきます。このモデルを Supervised Fine-Tuning (SFT)モデルと呼びます。
この章から InstructGPTモデルの論文に書かれている内容に入るので、 InstructGPTモデルの概要についても書いておこうと思います。
GPTモデルのパラメーター数を増やして精度を良くしたからといって、ユーザーの意図した答えを返せるようになるとは言い切れません。なので、人間からのフィードバックを利用することにより、ユーザーの意図した答えを返せるようにしたい、というのが InstructGPTの考えらしいです。実際にここからは、初めに作った GPTモデルを fine-tuningしていくことにより、人間が見て良いと感じる返答を返せるように頑張ることになります。この章で訓練する SFTモデルはその第一歩となります。ちなみに、ここからは会話用にモデルをチューニングするだけなので、一般的な NLPタスクにおける性能は徐々に下がっていきます。
訓練
ということで、 SFTモデルを訓練するのですが、訓練に使用するデータを自力で用意するのは大変です。なので、こちらのMasaさんのgithubからデータをお借りして、以前訓練した GPTモデルを fine-tuningしていこうと思います。
SFTモデルを更にチューニングしよう
概要
ここからは強化学習を使い、前回作った SFTモデルを更にチューニングしていくことになります。簡単に言うと、 SFTの生成した文章を採点するモデルを使い、 SFTモデルがより得点の高い答えを生成するように訓練します。そのために、以下のような工程が必要になります。
(1) SFTモデルに質問 (例: 吾輩は誰ですか?:)を投げて、答えをサンプリングする
(2) サンプリングした答えを人間が採点する
(3) 採点された答えを使って、採点をするNNモデルを作る (Rewardモデル)
(4) Rewardモデルを使い、 SFTモデルをさらにチューニングする (InstructGPTモデル)
最後に InstructGPTモデルと書いてある通り、これが最終章となります。では、一つ目のステップから見ていこうと思います。
SFTの答えをサンプリングする
答えのサンプリングをしていきます。ここでサンプリングされた答えは、次のステップで採点されることになります。ここで言う採点とは、実際に点数を付ける訳ではなく、同一の質問に対して複数の答えをサンプリングして、それらを順位付けするという形で行われます。なので、ここでは1つの質問に対して複数の答えをサンプリングします。
サンプリングするために使用する質問は、 SFTモデルを訓練した時に使ったものを再利用しようと思います。訓練時に使ったデータを再利用するのは良くない気もしますが、実装の簡略化ということで許していただけるとありがたいです。生成された答えはファイルに書き出されます。
サンプリングした答えを採点する
次に、モデルの答えを手動で採点します。ここで言う採点とは、同一の質問に対する複数の答えを順位付けするという形で行われます。なので、前のステップでファイルに出力した答えを、望ましい順に上から下に並べ替えることになります。
コード
- 採点例
Rewardモデルを訓練する
では、 SFTモデルの生成した答えを採点するモデル (Rewardモデル)を作っていこうと思います。 Rewardモデルは、アーキテクチャ的にはほぼ SFTモデルと同じです。唯一の違いは、最終層がスカラーを出力するということだけです。なので、 SFTモデルの最終層を取り替えた後に fine-tuningすることになります (実装の簡略化のため、今回の実装例では最終層を取り除かず追加だけしています) 。
ということで、 Rewardモデルを訓練するために以下の手順を繰り返します。
(1) 1つの質問と、それに対応する順位付けされた答え達を取ってくる。
(2) Rewardモデルでそれぞれの答えを採点する。
(3) 採点された答えを 2つ取ってきて、 を計算する (ここで
番目の答えは
番目の答えよりも手動採点の順位が高いものとします)。
(4) 3の値を全ての答えのペアに対して計算し、その平均を損失としてモデルを訓練する。
では、以下のコードでモデルを訓練していこうと思います。
InstructGPTモデルを訓練する。
では、最後に強化学習 (RL)を使って InstructGPTモデルを訓練します。 InstructGPTモデルは、 SFTモデルを以下の目的関数に対して fine-tuningすることにより作成されます (論文)。
- : 質問
- : 答え
- : 質問
と答え
に対して、 Rewardモデルの出力する点数
- : InstructGPTモデルが質問
に対して、答え
を生成する確率
- : SFTモデルが質問
に対して、答え
を生成する確率
- : 重み付けのハイパーパラメーター
- : 重み付けのハイパーパラメーター
- [f(x)]:
を一般 GPTモデル訓練用のデータから取ってきた時のf(x)の平均値
] についてですが、これは Proximal Policy Optimization (PPO)というテクニックから来ています。軽く説明をすると、本来であれば 1項目の Rewardモデルの項だけで訓練したいです。ただ、それだけだとモデルのパラメーターが急激に変化しすぎてしまい、訓練が不安定になるかもしれません。なので、 2項目の
という KL-divergenceを加えることで、元の SFTモデルから距離が離れすぎないようにしています。また、実装例にも含まれていますが、目的関数だけではなく、トレーニングの方でも Clipped Surrogate Objectiveと呼ばれる手法が使われています。申し訳ないのですが、 PPOについての詳しい説明は、元論文やめんだこさんのブログなどを参照してくださると助かります。
最終項についてですが、これは通常の GPTモデル用の目的関数となっています。 InstructGPTモデルは元の GPTモデルに比べ、一般的な NLPタスクに対しての性能が悪くなってしまいます。なので、ある程度の汎化性能を残そうということらしいです。今回は実装の簡略化のため、 を採用して、論文中でいうところの PPOモデルを実装しようと思います。 InstructGPTと呼ばれるモデルは
を採用しています。
ということで、以下が最後の実装となります。
コード
- 実装例 (こちらの実装も参考になると思います)
- 実行例
最後に
InstructGPTの実装、お疲れ様でした。ここまでお付き合いいただき、ありがとうございました。
コドゲのコンペ前日チェックリスト
CodinGameの大きなコンペが半年に一度しかなく記憶を失いがちなので、コンペに必要な知識をここに残しておきます。
モンテカルロ木 、Mini-Max木
まずはこの記事を読む。
2人同時にプレイするゲームではDUCTを使う。
AlphaZeroを使えるならAlphaZero一択。AlphaZeroの元論文はいくつかのバージョンが存在するがこれが一番詳細なはず。17ページ目のSearchセクションに必要なことが全て書いてある。
ランダム性のあるゲームには Information Set MCTSを使う。ネットで探しても資料はあまり見つからない。とりあえず似たようなノードがあれば1つに纏めて上手く行くことを願う。
焼き鈍し、ビームサーチ、何らかの探索
使える時は絶対に使う。綺麗に使えない時も使ったほうがいい。使ってる解法と使ってない解法だと使ってる方が確実に強い。無理だと思っても無理やり使ったほうがいい。
手元でシミュレーターを走らせる
以下の記事にしたがって手元でシミュレーターを走らせておく。mvn等のインストールが必須なので実際に走らせておくこと。コード構成などのマイナー変更で記事通りに走らせられなくなる可能性もあるので、動く原理も理解しておいたほうがいい。コンペ中に動かなかった場合はDiscordのコンペ用チャンネルで聞くと答えてくれる。
Discord
CodinGameのこのページにDiscordへのリンクが貼ってある。コンペ用のチャンネルがあるので何かあった時はそこに書くといい。コドゲのフォーラムよりも活発な感じがする。
コドゲのシミュレーターを手元で走らせる方法 2023
本記事は、中身をある程度理解した上でSpring Challenge 2023のシミュレーターをローカルで走らせようというものになっています。賢く手軽に走らせたいという方はボンドさんの記事などを参考にした方がいいかもしれないです。
本記事では、初めにビジュアライザ上で自分のボットを走らせた後に、ビジュアライザを起動せずに連続で試合を回せるようにしていきます。
http://localhost:8888/に何かを表示させる
ビジュアライザを完璧に走らせるには複数のステップを踏む必要がある。まずはバグった状態のローカルサーバーを建て、そこから目で確認できる形でバグを1つずつ直していく。
ローカルサーバーを建てるエントリポイントがsrc/test/java/Spring2023Main.javaにある。src/testの下にあるファイルはコンパイル後のjarに含まれないので、以下のコマンドでsrc/mainに移動する。
mv src/test/java/Spring2023Main.java src/main/java/
以下のコマンドでコンパイル。
mvn assembly:assembly -DdescriptorId=jar-with-dependencies
target/spring-2023-ants-1.0-SNAPSHOT-jar-with-dependencies.jarが生成される。以下のコマンドでローカルサーバー起動。
java -cp target/spring-2023-ants-1.0-SNAPSHOT-jar-with-dependencies.jar Spring2023Main
http://localhost:8888/にアクセスできるようになっている。
壊れているので紺色のページが表示される。

TypeScriptでJavaScriptを生成する
先程の紺色のページのエラーメッセージを見てみるとViewModule.jsをロードできなかったと書いてある。CodinGameは最近TypeScriptを使うようになったらしくTypeScriptからJavaScriptを生成する必要があるらしい。しかし、ド素人なのでよくわかってはいない。
${root}/typescriptというディレクトリがあるがこれは関係がない。実際には${root}/src/main/resources/view/ts内のファイルをトランスパイルする必要があり、以下のコマンドでどうにかなる。最後のyarn startはtscをwatchモードで起動し待機状態に入るので、適宜自分で終了する必要がある。
cd src/main/resources/view/ yarn install yarn start
これでsrc/main/resources/view/graphcis内にJavaScriptが生成された。余談だが、npm ci; npm run startを走らせろというコメントをよく見るが、CodinGameの社内レポジトリを参照しようとするらしく動かない。yarn install; yarn startだと動く。理由は不明。
何はともあれJavaScriptが生成されたので再びローカルサーバーを建ててみる。
mvn clean assembly:assembly -DdescriptorId=jar-with-dependencies java -cp target/spring-2023-ants-1.0-SNAPSHOT-jar-with-dependencies.jar Spring2023Main
http://localhost:8888/にアクセスすると多少直ったページが表示される。

画像を正しい場所に置く
先程のページのエラーメッセージを見てみると/assets/assets/spritesheet.pngにアクセスできないと言っている。ただ、/assets/spritesheet.pngにはアクセスできる。つまり何故かURL内でassetsがダブる仕様になっている。このspritesheet.pngはsrc/main/resources/view/assetsディレクトリから来ており、そのディレクトリ内の全てのファイルに同様の仕様が適用される。なのでassets内のファイルだけをassets/assetsに移動するようにMavenにお願いする。
{kind=link}
{kind=link}
assembly.xmlをルートディレクトリ下に作成し、以下の内容をコピペする。
<assembly xmlns="http://maven.apache.org/ASSEMBLY/2.1.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/ASSEMBLY/2.1.0 http://maven.apache.org/xsd/assembly-2.1.0.xsd"> <id>jar-with-dependencies</id> <formats> <format>jar</format> </formats> <includeBaseDirectory>false</includeBaseDirectory> <dependencySets> <dependencySet> <outputDirectory>/</outputDirectory> <useProjectArtifact>true</useProjectArtifact> <unpack>true</unpack> <scope>runtime</scope> </dependencySet> </dependencySets> <fileSets> <fileSet> <directory>${project.basedir}/src/main/resources/view/assets</directory> <useDefaultExcludes>true</useDefaultExcludes> <outputDirectory>/view/assets/assets</outputDirectory> </fileSet> <fileSet> <directory>${project.basedir}/src/main/resources/view</directory> <useDefaultExcludes>true</useDefaultExcludes> <outputDirectory>/</outputDirectory> <excludes> <exclude>view/assets/**</exclude> </excludes> </fileSet> </fileSets> </assembly>
assembly.xmlを指定してMavenでコンパイルする。
mvn clean assembly:assembly -Ddescriptor=assembly.xml
以下のコマンドでローカルサーバー起動。
java -cp target/spring-2023-ants-1.0-SNAPSHOT-jar-with-dependencies.jar Spring2023Main
http://localhost:8888/にアクセス。これで問題なく動くはず。ゲーム画面が動いていない用に見えるが、これはデフォルトのボットが何もしないため。ビジュアライザのセットアップはおしまい。

自分のボットを戦わせる
初めに移動したローカルサーバーを起動するためのMainクラスsrc/main/java/Spring2023Main.javaの中でgameRunner.addAgentが呼ばれているが、この引数としてボットの実行コマンドが渡されている。なので、そこを自分のボットを起動するコマンドに書き換えればいい。
- gameRunner.addAgent("python3 config/Boss.py", "TestBoss_1"); - gameRunner.addAgent("python3 config/Boss.py", "TestBoss_2"); + gameRunner.addAgent("/home/nanaeda/main"); + gameRunner.addAgent("/home/nanaeda/main");
Spring Challenge 2023はリーグによって入力形式が変わるため、src/main/java/Spring2023Main.java内のgameRunner.setLeagueLevelの引数を適切な値に変更しないと入力を受け取る所で止まったりする。どのリーグレベルの数値がWoodやGoldに対応するかはよくわからないので、コード中でリーグレベルの値が使用されている所を確認するとよい。
- gameRunner.setLeagueLevel(3); + gameRunner.setLeagueLevel(4);
src/main/java/com/codingame/game/Referee.java内でのリーグレベルの使用方法を確認した結果、レベル4以上から入力にスコアが追加されるらしい。
int leagueLevel = gameManager.getLeagueLevel(); if (leagueLevel == 1) { Config.FORCE_SINGLE_HILL = true; Config.ENABLE_EGGS = false; Config.LOSING_ANTS_CANT_CARRY = false; Config.MAP_RING_COUNT_MAX = 4; } else if (leagueLevel == 2) { Config.FORCE_SINGLE_HILL = true; Config.LOSING_ANTS_CANT_CARRY = false; Config.MAP_RING_COUNT_MAX = 5; } // level 3 = interactions, big map, multiple hills if (leagueLevel >= 4) { Config.SCORES_IN_IO = true; }
いつも通りコンパイルしてサーバーを起動する。
mvn clean assembly:assembly -Ddescriptor=assembly.xml java -cp target/spring-2023-ants-1.0-SNAPSHOT-jar-with-dependencies.jar Spring2023Main
http://localhost:8888/にアクセスすると動いているはず。

連続で試合を回す
今まではMainクラス内でMultiplayerGameRunner::startを呼び、ビジュアライザを起動していた。これをMultiplayerGameRunner::simulateに変更するとビジュアライザを起動せずに対戦だけを行うことができる。例えば、以下のようなコード変更をsrc/test/java/Spring2023Main.javaに行うことができる。
import com.codingame.gameengine.runner.MultiplayerGameRunner; +import com.codingame.gameengine.runner.simulate.GameResult; import com.google.common.io.Files;
gameRunner.setLeagueLevel(4); - gameRunner.start(); + final GameResult result = gameRunner.simulate(); + System.out.println("Player0 score=" + result.scores.get(0)); + System.out.println("Player1 score=" + result.scores.get(1)); }
コンパイルと起動方法は前回と同じ。
mvn assembly:assembly -Ddescriptor=assembly.xml java -cp target/spring-2023-ants-1.0-SNAPSHOT-jar-with-dependencies.jar Spring2023Main
アウトプット例は以下の通り。
Player0 score=66 Player1 score=80
これで対戦だけを回すことができるのだが、CodinGameのコードはJava起動時に初期化されたグローバル変数をそのまま使っている可能性が高い。つまり、forループで対戦を回すとバグるかもしれない。なので対戦毎にJavaを起動すると安全。
コドゲのシミュレーターを手元で走らせる方法 2022
こっちに最新バージョンがあるぞ!
Diffusionモデルで猫を生成しようとした話
Diffusionモデルを自分で実装し、ノイズから猫を生成しようとした時の備忘録。

- 1~10日目: VAEが難しい
- 11日目: Diffusionモデルは簡単
- 12日目: 実装用の論文を読んだ
- 13~20日目: MNIST攻略
- 21日目: Open Imagesは難しい
- 22~25日目: Unetの実装を変えた
- 26~30日目: PyTorchの最適化をした
- 31~60日目: ターゲットを猫に絞る
1~10日目: VAEが難しい
Diffusionモデルの解説記事を読むと、VAEという他の画像生成アルゴリズムが関係あると書いてあったので、そっちから入ることにした。このサイトの解説が詳しかったので参考にした。ただベイズ自体がかなり怪しくなっていたので、実際には同サイトのEMアルゴリズムや変分ベイズから始めることになった。
ベイズは抽象的な話が続いてパニックに陥ることも多かったので、このあたりの練習問題的なものを随時解いていた。
11日目: Diffusionモデルは簡単
Diffusionモデルの解説記事を読んだが、VAEに似ていたので簡単だった。Langevin dynamicsだけはよくわからなかったが、わからなくてもあまり問題はなかった。
12日目: 実装用の論文を読んだ
実装するにあたり、細かい情報も欲しいのでこの論文を参考にした。出発地点としては良い選択であったが、後で改良の為に別の論文も参考にした。
13~20日目: MNIST攻略
実装はかなり簡単で、MNISTから数字を生成できるようになった。余談ではあるが、MNISTのデータを取ってくる綺麗な方法がなくて、結局TensorFlowから取ってきた。トレーニング時間はかなり短く、おそらく数十分~数時間くらいだった気がする。
21日目: Open Imagesは難しい
上で実装したコードをOpen Imagesに適応したが、何かしらの意味ある画像を生成することはなかった。Unetの実装が悪かったのか。NNのサイズが小さかったのか。とりあえず、そのあたりを改善していくことにした。
22~25日目: Unetの実装を変えた
実装の参考にする論文をこっちに変えた。おそらくその論文に使われたであろうコードも見つけたので、Unetの実装はそこを参照した。
26~30日目: PyTorchの最適化をした
参考にした論文では、そこそこ大きいモデルを使っていたらしい。正直思ったよりもかなり小さかったが、それでもそこそこ大きいので工夫が必要だった。
試行錯誤の末、最終的には16GBのGPUを2つ使い、分割されたモデルの半分を一方のGPUに置き、もう半分をもう一方に置くことにした。それでもメモリ使用量がすごかったので、Gradient checkpointingを使った。
トレーニングはパイプライン方式を採用した。Unetをパイプラインでトレーニングするのは難しいかと思ったが、インプットからアウトプットまで一気に計算させずに、ネットワークの前半部分だけを全バッチに対してパイプラインで計算して、その後に後半部分をパイプラインで計算すればどうにかなった。
31~60日目: ターゲットを猫に絞る
モデルや訓練をいくら最適化してもOpen Imagesで動く気配はなかった。そこで、もしかしたら画像の種類が多いのかなと思った。確かに言われてみれば、GAN系の論文はベッドルームばかり生成していた。あれはベッドルームを生成するのが比較的簡単だからだったからなのかなと思った。
ということで猫の画像にターゲットを絞ることにした。結果は上澄みを集めて以下の感じ。

ただ、80%以上の確率で黒い画像やモヤみたいな物を生成していた。見栄えの観点から、画像サイズを64x64に設定していたが、訓練に数日かかってキツかった。32x32にしたり、ベッドルームの生成に切り替えてたら、もっと安定して綺麗に生成できていたのかもしれない。バグってる可能性を排除できないのもキツかった。
ここから改良しようとすると、あとはパラメーターを変えたり重課金するくらいしか思いつかず、学びが少ないかなと思い、ここで一旦終了することにした。
文字列から画像を生成するのも流行っているが、そちらもかなり似たアルゴリズムで実現可能らしいので、いずれ機会があれば実装してみたい。
AlphaZeroでオセロのボットを作った話
AlphaZeroでオセロのボットを作成し、人類(クソデカ主語)では勝てないほどの棋力を得たので、そこに至るまでの2ヶ月に渡るあれこれなど。
AlphaZeroとその前身であるAlphaGoは基礎的なアルゴリズムが大きく違い、かつAlphaZeroの方がかなりシンプルである。それに気づかずAlphaGoの論文を読み実装を始めてしまったため、かなりの時間を無為に浪費するところから始まった。 その後、Arxivに上がっていたAlphaZeroの論文を読み実装に勤しんだが、実はもっと詳細なバージョンの論文が存在するという罠にも引っ掛かっており、これがかなり尾を引いた。 Golangなるモノを聞いたことがあった。時代についていけていないので、これまで触れもせず遠目に眺めているだけであったが、意を決してGolangで実装することにした。結果、特にさしたるドラマもなく動いた。よい。 作成したUIには相手のターンや自分のターンといった概念はなく、自分で好きなところに置くかボットに打たせるかを常に任意で選べるようにした。好きな盤面を作ってからボットに打たせたりできるのでこれもよい。 Pythonで実装した。動きはしたが速度に難有りだったので、その改善がメインとなっていった。 石を置けるかなどの判定をPythonで実装していると非常にスピードが遅くなってしまうのでC++に移植した。Boost.Pythonを使った。以前、BoostやCythonを使おうとした時は非常に苦労した覚えがあったので身構えていたが、わりと簡単に実装できて驚いた。年々Stack Overflowなどに知見が溜まっていき嵌りどころが解消されていっている。集合知。 Tensorflowを複数のPythonスレッドで走らせることに難儀した結果、Tensorflow Servingという独立で走る推論サーバーを使用することにした。Tensorflow Servingを使えば、複数のスレッドから送られたデータをバッチ化してスコアリングしてくれるので速度的にも有り難い。 TCPリクエストにconnection=closeを付与せずに連続で送り続けると、何らかのリソースを使い切ってしまいRESTリクエストが一定時間送れなくなるという罠にずっとハマっていた。何もわからずgRPCを使っていたのでgRPCでも同じ問題に陥っていた。ただ、どちらのケースも一度開いたチャンネルを再利用すれば問題を回避できるし速度面でも有利ということに後に気づいた。 GCPを使ったことがなかったので使ってみた。無料で数万円分使えるという太っ腹。基本的には24CPU1GPUのマシンで回していた。 如何ともし難く遅かった。主な原因としてはAlphaZeroのアルゴリズムを勘違いしていたことがある。AlphaGoとは違い、AlphaZeroはMCTSにおいてロールアウトをせずNNの出力をノード評価値として使用するのだが、そのことに最終盤まで気づかなかった。ロールアウトは非常に時間がかかるので致命的なミスであった。 トレーニングが遅いから弱いという単純な理由だった。ただ時間をかければ強くなっていっている感じもした。 可能な限りC++に移植しようとした。TensorflowでモデルをトレーニングするのはC++では厳しいのでPythonに残しておいたが、残りはほぼ全てC++に移植した。同時にMCTSを並列アルゴリズムに変えた。もともと並列に複数の自己対戦を行い棋譜を生成していたので、トレーニングの高速化に寄与したかは怪しい。ただ1戦1戦を高速に回せるのでNNの世代を速く回せるという利点はあるのかなと思った。ローカルでボットと対戦する際は非常に役に立った。 C++への移植に伴いgRPCコールもC++から呼ぼうと思った。これがあまりにもキツかった。そもそもの難易度が高く、ネット上でも苦しんでいる人々が散見された。それにLinuxやC++への理解の低さもかなり響いた。おそらくではあるが、適切なprotoファイルをTensorflowのレポジトリから選び出し、C++用のコードを生成して使えば何とかできるのだろうと思った。ただ、自分の場合はそこからBoost.Pythonを使い.soファイルを作りPythonから呼ばなければならず、更に難易度が上がってしまった。結果、うまく動かすことができずRESTコールでお茶を濁すこととなった。たぶん、このRESTコールが最終的なボトルネックになったと思う。PythonからC++を呼ばず、C++からPythonを呼ぶようにしておけば話は違ったと思う。 案外すぐに無料分を使い果たしてしまった。ここまではわりとのんびりと進めていたのだが、ここから凄いスピードで進捗を出していくことになった。良くも悪くも身銭を切ると緊張感が変わってくる。 一通りのことはやったので再び元の論文を読み、野良ブログなども読み漁った。ロールアウトがいらないと気づいたのもこの時であった。詳しい方の論文にだけMCTSの実装詳細が書いてあってそこで気づいた。その他にも小さな改善を繰り返していった。 この時点でわりと高速に自己対戦し棋譜を生成できるようになっていた。正確には24CPU/1GPU(P4)のマシンで、Resnet(channel=72, depth=13)を使用し、MCTS(n=800)で毎分12棋譜を生成できた。 夜にトレーニングを開始して朝に対戦してみても、自分(私は人間です)では勝てなくなった。ネット上にCodinGame1位のボットが公開されているが、十分な持ち時間のハンディキャップ(MCTS[n=6400])があれば、1日訓練してたまに勝てるくらいにはなった。ただ、もう1日訓練してから戦ってもあまり勝率は上がらなかった。理由はわからない。小さめのモデルを使っていたのがダメだったのか、実は棋力の差が思った以上に大きかったのか。 折角2ヶ月も掛けたので、ブログを書いたり動画を作ってみてもよいのではと思い、今このブログを書いています。日記などは付けていなかったので、夏休みの宿題方式で朧気な記憶を掘り起こしつつ書いています。しかし、少しばかりブログの締めくくり方に難儀しています。 なので最後にGCPの請求額を書いて終わろうと思います。
0〜14日目:AlphaGoの論文だけを読んでしまう
14~16日目: UIを作る
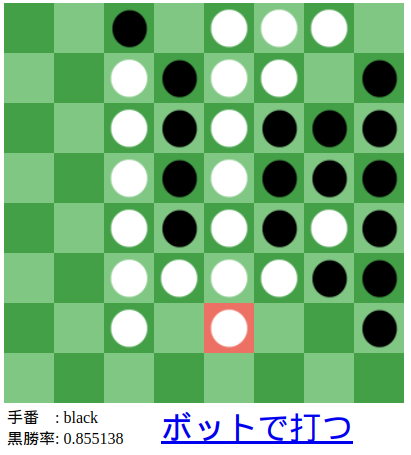
17~20日目: AlphaZero実装
21~22日目: C++で高速化
23~27日目: Tensorflow Servingを使う
28日目: GCPを使ってみる
29日目: トレーニングが遅い
29日目: ボットが弱い
28~30日目: 全てをC++に移植し並列MCTSに
31~33日目: C++でのTensorflow Serving gRPCコールが難しすぎる
34日目: GCPの無料分が尽きる。
35~36日目: 再びAlphaZeroに関する情報をチェックする
37日目: ボットが最強になった
最終日: ブログとGCPの請求額
無料分が切れてからは怖くて請求額は見てなかったです。
たぶん1.5万円くらいだとは思いますが。
ということで今からGCP開いてきます。
.
.
.
13,536円でした。ん〜妥当。
CodinGame Spring Challenge 2022で3位を取った話
CodinGameのSpring Challenge 2022というゲームAIコンテストにおいて18,288人中3位を取ることができたので、コンテスト中の考え方や解法などを残しておこうと思います。

準備期間について少し
CodinGameという名前を知ってはいましたが実際に出場したことはなかったため、コンテスト開催一ヶ月前からCodinGame上の課題を解いて練習しておこうと思いました。僕が選んだ課題はUltimate Tic-Tac-ToeというものでチェスのようなボードゲームのAIを作るというものです。そこで僕はモンテカルロ木探索を学び、AlphaZeroやNNUEを自前で実装し、来るべきコンテストに備えました。そして迎えたコンテスト当日、はやる気持ちを抑えつつ問題文に目を通すと、そこにはルール無用超次元サッカーが広がっていました。
取り組み方の基本方針
問題を読んだ感じ、今回のコンテストは理不尽ムーブの押し付け合いになるのかなという印象を受けました。ただ、攻撃のバリエーションが豊富にあるため、どの攻撃方法を実装すればいいかわからず攻撃ロジックの実装は切りがないなと思いました。また、マナや視界には限りがあり、異なる盤面のセットアップも必要になるため、複数の攻撃方法を採用するのも難しそうだと感じました。なので、初日から攻撃ロジックを実装していっても、攻撃方法を変えた時点で全てのコードを破棄することになり無駄になるのではと思いました。
反面、防御関連のロジックは攻撃と違い積み重ねが効くと感じました。ある攻撃方法に対する防御用の実装を書いた場合、たとえその攻撃方法が廃れてもコードは残しておいて常にif文で起動することができるようにしておけるからです。しかし、序盤に使われる攻撃方法はたぶんそんなに対策する価値がないだろうなという考えから初日に防御関連のロジックを実装するのも微妙かなと思いました。
ということで初日から攻撃も防御も実装しないこととなり、ゲームAIの大会でボットも作らずライブラリを作り込み続けるという日々が始まりました。
ボット概要
防御型のボットとなりました。120ターン目までは全ヒーローを使用して防御とマナ集めに徹し、そこから攻撃に移行するという戦法になっています。攻撃方法は虫にシールドをかけた上で相手をコントロールしつつ飛ばすという、時間はかかるがマナ消費を抑えられ防ぎにくいものを採用しました。
序盤から強めに攻めてくるボットにはマナ枯渇を狙え有利となっています。逆にあまり攻めてこないボットに対しては、必要以上に防衛してしまいこちらのマナが枯渇するのでかなり不利なマッチアップとなっています。上位陣は前者の攻めてくるボットが多いため、この戦法を選びました。
この記事の上の方で、防御は難しそうと書いていましたが実際はそこまででもなかったです。攻撃型のボットが乱立した結果、攻撃型同士の戦いに勝つために不完全な状態で早めに攻撃を仕掛けることになり、防御しやすくなったのではと思っています。漁夫の利。
ボット実装
相手の行動を考慮に入れた探索などはせず、現在の敵・味方・虫の位置からルールベースで次の行動を決めています。ただ前述の通りライブラリだけは充実しているので、何ターン後に虫に追いつき魔法を打てるか、そのためにはどこに向かえばいいか、虫がゴールに行くのを阻止できるか、などといったことは予め知っています。それらの情報から魔法を打つべきか動くべきかなどの行動を決めます。そして最後にどこに動くべきかなどをヒューリスティックの評価関数で決定しています。
実装面でもロジック面でも特筆すべき点は特にないように感じます。色々な情報を正確かつ手軽に入手できるように実装を固めておき、対戦のリプレイを通じて得た知見を簡単にボットに反映できるようにすることに集中していました。
感想
想定と大きく違うタイプのコンテストでAlphaZeroもNNUEも一切使わなかったけど、とりあえず楽しかった。ガムシャラに色々なモノを実装するのではなく、忙しくなるコンテスト後半に備えて実装を固めて準備できたのが人間としての成長を感じた。